Agent Skills - The Cognitive Architecture of Autonomous Systems

This deep dive analyzes the evolution of Agent Skills—a critical paradigm shift from static tool use to dynamic, autonomous capability acquisition.
2026-01-12T00:00:00.000Z
Agent Skills - The Cognitive Architecture of Autonomous Systems
For the past few years, we have witnessed a Cambrian explosion in Large Language Model (LLM) capabilities. However, as practicing engineers and architects, we know that a raw model—no matter how many parameters it possesses—is effectively a brain in a jar. It can think, reason, and hallucinate, but it cannot act.
The transition from "Chatbot" to "Agent" is defined by the ability to interact with the external world. This capability is encapsulated in what we now call Agent Skills. A skill is not merely a function call; it is a cognitive primitive that combines definition, execution logic, and error handling into a unit of work that an autonomous system can wield.
In this article, we will dissect the cognitive architecture required to support robust agent skills. We will move beyond simple API wrappers to explore how agents discover, learn, and orchestrate complex capabilities to solve open-ended problems.
Contents
- The Anatomy of a Skill
- From Static Tools to Dynamic Affordances
- The Executive Function: Orchestration and Planning
- Skill Acquisition and Self-Correction
- The Memory Hierarchy in Skill Execution
- Standardization: The Model Context Protocol (MCP)
- The Safety Sandbox: Runtime Environments
- Conclusion
1. The Anatomy of a Skill
When we engineer agent systems, we must first define what constitutes a "skill." In traditional software development, a function is a block of code with inputs and outputs. In the context of an autonomous agent, a skill is a semantic wrapper around that function.
A robust skill consists of three distinct layers:
- The Interface (Schema): Usually defined in JSON or TypeScript interfaces, this tells the LLM what arguments are required. It acts as the contract.
- The Docstring (Semantics): This is arguably more critical than the code itself. It describes when and why the skill should be used. The LLM uses this natural language metadata to perform semantic matching against the user's intent.
- The Implementation (Executable): The actual Python, JavaScript, or SQL code that performs the side effect.
We have found that the quality of an agent's performance correlates more strongly with the clarity of the "Docstring" layer than the underlying model size. If the agent cannot understand the utility of a tool via its description, the tool effectively does not exist.
2. From Static Tools to Dynamic Affordances
In the early days of LangChain and AutoGPT, "tools" were hardcoded. An engineer would manually write a GoogleSearch function and pass it to the agent. This is static tooling.
However, we are seeing a paradigm shift toward Dynamic Affordances. This concept draws from ecological psychology—an affordance is an opportunity for action provided by the environment.
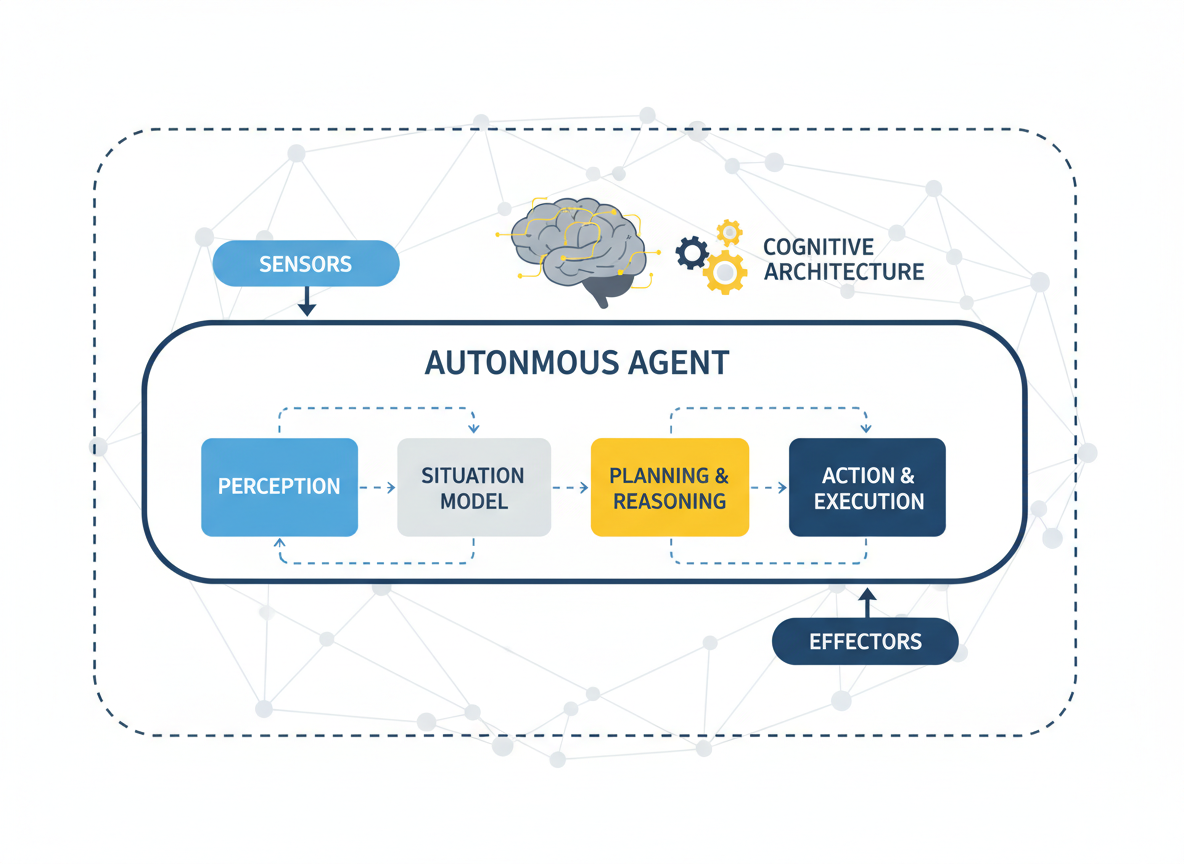
In advanced architectures, agents don't just have a list of tools; they have a mechanism to retrieve relevant skills based on the current context. Imagine an agent with access to 5,000 internal API endpoints. We cannot stuff 5,000 schemas into the context window. Instead, we use a retrieval step (often vector-based) to fetch the top $N$ most relevant skills for the current task.
This transforms the architecture from a static Swiss Army knife into a dynamic workshop where the agent pulls tools off the shelf only when needed.
3. The Executive Function: Orchestration and Planning
Possessing a skill is different from knowing how to use it. The "Executive Function" of an agent is the control loop that governs skill selection. This is often implemented using reasoning frameworks like ReAct (Reasoning + Acting) or OODA loops (Observe, Orient, Decide, Act).
In our architectural patterns, we often separate the Planner from the Executor.
- The Planner breaks a high-level goal ("Research competitor pricing") into a Directed Acyclic Graph (DAG) of necessary steps.
- The Executor takes a step, selects the appropriate skill, executes it, and observes the output.
Crucially, the output of a skill—the observation—must be fed back into the context. If a database query fails, the Executive Function must detect the error and decide whether to retry with different parameters or switch strategies entirely. This feedback loop is what differentiates a script from an agent.
4. Skill Acquisition and Self-Correction
Perhaps the most exciting development in cognitive architectures is the ability for agents to create their own skills. This was famously demonstrated by the Voyager agent in Minecraft, which used GPT-4 to write code for new behaviors, test them, and save the successful code to a "Skill Library" for future use.
This process generally follows a specific lifecycle:
- Generation: The agent writes code to solve a novel problem.
- Verification: The code is executed in a sandbox.
- Refinement: If execution fails (syntax error or logic error), the error trace is fed back to the LLM for self-correction.
- Crystallization: Once the code succeeds, it is stored (e.g., in a vector database) with a generated description.
This moves us toward "Open-Ended Learning." An agent deployed today might have 10 skills. Next month, after encountering unique edge cases in production, it might have synthesized 50 new specialized skills without human intervention.
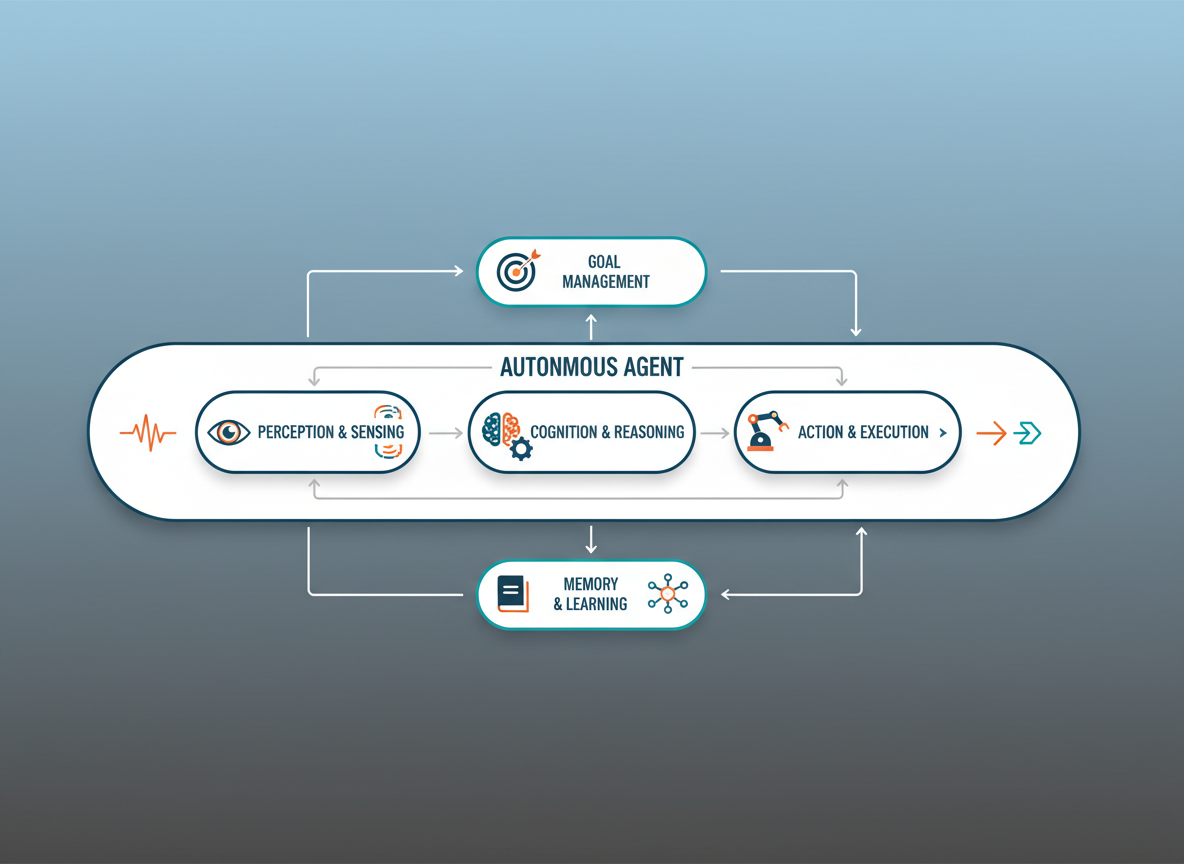
5. The Memory Hierarchy in Skill Execution
Skills do not operate in a vacuum. They require state. We treat agent memory not as a monolith, but as a hierarchy similar to computer architecture:
- Sensory Memory: The raw input from the user or environment (current prompt).
- Working Memory: The context window. This contains the active plan, the immediate history of tool outputs, and the current reasoning trace.
- Episodic Memory: A vector store containing logs of past trajectories. "How did I solve a similar SQL error last week?"
- Procedural Memory: The Skill Library itself. This is the repository of how to do things.
Effective skill execution relies on the interplay between Working Memory (the current variables) and Procedural Memory (the function definitions). If the Working Memory is overloaded, skill hallucination increases. Therefore, managing the context window by summarizing past skill outputs is a vital architectural pattern.
6. Standardization: The Model Context Protocol (MCP)
As we scale agent systems, we encounter the "N-to-M" problem. We have N different AI models (Claude, GPT-4, Llama) and M different data sources (Postgres, Slack, GitHub). Building custom connectors for every combination is unsustainable.
This is where the Model Context Protocol (MCP) becomes essential.
MCP provides a universal standard for exposing data and tools to agents. Instead of writing a specific "Slack Tool for LangChain," developers create an MCP Server for Slack. Any MCP-compliant client (whether it's Claude Desktop or a custom Python agent) can instantly discover and utilize those resources.
By standardizing the "handshake" between the agent and the skill, we decouple the cognitive engine from the tool implementation. This allows us to build modular, interoperable agent ecosystems where skills are portable across different model architectures.
7. The Safety Sandbox: Runtime Environments
When we allow agents to select skills—and especially when we allow them to write skills—security becomes the paramount concern. An agent with a "Shell Execution" skill is effectively a remote code execution (RCE) vulnerability waiting to happen.
We must implement strict Sandboxing.
- Containerization: Skills should run in ephemeral Docker containers or Firecracker microVMs.
- WASM (WebAssembly): For lighter-weight isolation, compiling skills to WASM allows us to execute untrusted code with granular capability constraints.
- Human-in-the-Loop: For high-stakes skills (e.g.,
delete_database,transfer_funds), the architecture must enforce a human approval step.
We treat the agent's generated code as "untrusted user input." It is never executed directly on the host machine's metal. The cognitive architecture must include a "Guardian" layer that validates the safety of a skill call before it is routed to the execution environment.
8. Conclusion
The evolution of Agent Skills represents the maturation of AI from a passive knowledge engine to an active participant in our digital economy. We are moving away from monolithic prompts toward modular, composable cognitive architectures.
By focusing on dynamic retrieval, self-correction, standardized protocols like MCP, and robust sandboxing, we are laying the foundation for autonomous systems that are not only intelligent but also reliable and safe. As architects, our role is to build the scaffolding—the memory systems, the planners, and the runtimes—that allows these agents to master their skills and, ultimately, assist us in solving the world's most complex engineering challenges.