Agentic RAG - The Cognitive Core of Autonomous AI

Retrieval-Augmented Generation (RAG) is evolving from a static lookup mechanism into the dynamic cognitive core of autonomous AI agents. While traditional RAG simply fetches data, Agentic RAG reasons, plans, and iteratively refines its search strategies.
2026-01-07T00:00:00.000Z
Agentic RAG - The Cognitive Core of Autonomous AI
If you were building an AI application in 2023, Retrieval-Augmented Generation (RAG) was likely a linear pipeline: a user asked a question, you embedded it, performed a cosine similarity search in a vector database, stuffed the top-k chunks into a prompt, and hoped the LLM made sense of it.
That was "Naive RAG." It was a librarian that couldn't read the books it handed you—it just matched the keywords on the spine.
Today, in 2026, we have moved beyond static retrieval. We are building Agentic RAG. We are no longer building pipelines; we are building cognitive loops. In this architecture, the LLM is not just a text synthesizer at the end of the chain; it is the reasoning engine—the "Brain"—that actively controls the retrieval process, evaluates the quality of the found data, and decides when it knows enough to answer or when it needs to dig deeper.
This article dissects the architecture of Agentic RAG, exploring how we transitioned from passive lookup to active reasoning.
Contents
- From Passive Retrieval to Active Reasoning
- The Agentic Architecture: Router, Retriever, and Grader
- The Cognitive Loop: ReAct and Plan-and-Solve
- Tool Use: The Interface Between Reason and Data
- Self-Reflection and Error Correction
- Memory Systems in Agentic Workflows
- Production Challenges: Latency and Guardrails
- Conclusion
1. From Passive Retrieval to Active Reasoning
The fundamental limitation of standard RAG was its determinism. It assumed that a single retrieval step based on the initial user query would yield the perfect context. However, complex engineering problems or ambiguity in user intent often break this assumption.
If a user asks, "Compare the latency implications of gRPC vs. REST for our microservices architecture considering our current load balancer config," a standard RAG pipeline might fetch generic articles on gRPC and REST. It fails to fetch the specific "load balancer config" because the semantic weight of the generic terms overpowers the specific internal documentation.
Agentic RAG flips the control flow.
Instead of:
Input -> Retrieve -> Generate -> Output
We have:
Input -> Reason -> Plan -> Retrieve (maybe) -> Evaluate -> Re-Retrieve (if needed) -> Generate
In an agentic system, the model analyzes the query and breaks it down. It might decide it first needs to find the "current load balancer config." Once it retrieves that, it analyzes the configuration then formulates a new query to compare protocols based on those specific constraints. It acts less like a search engine and more like a research assistant.
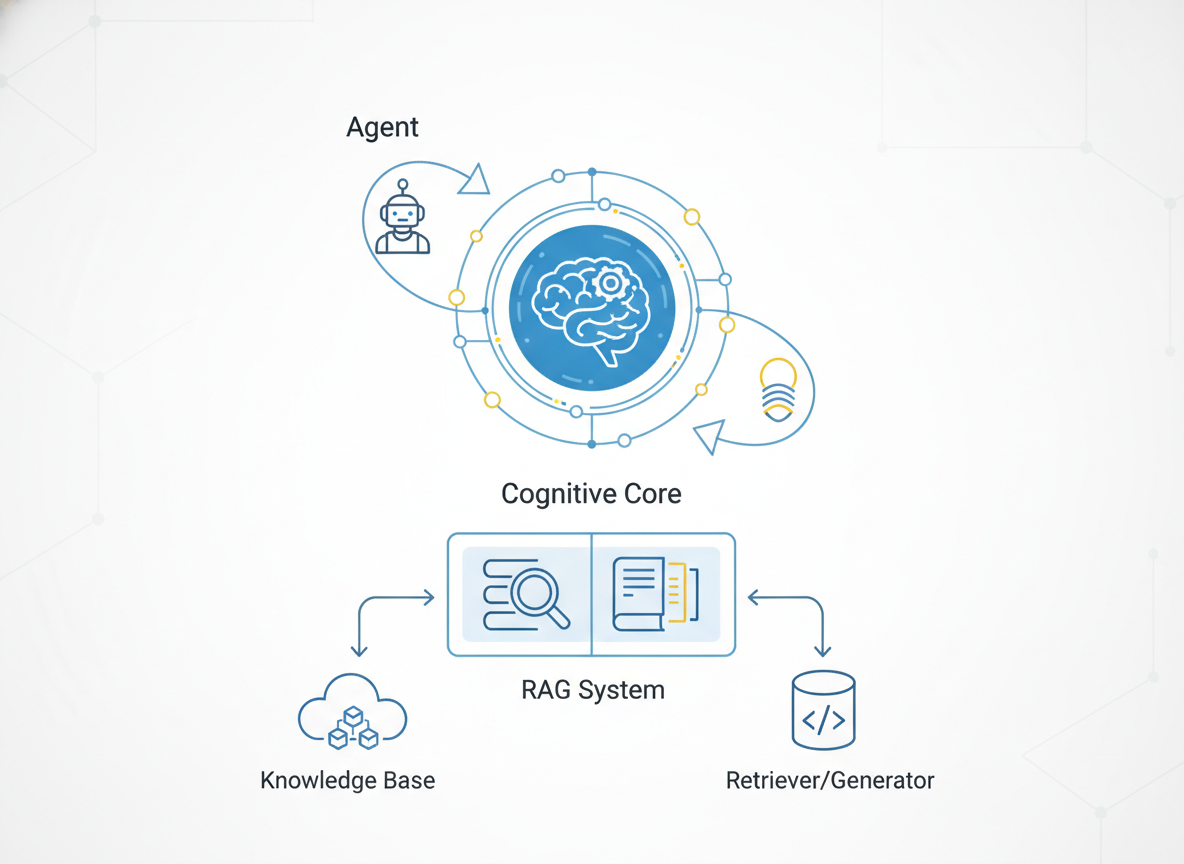
2. The Agentic Architecture: Router, Retriever, and Grader
To implement Agentic RAG, we must modularize the monolith. We break the system into specialized functional components (often managed by a framework like LangGraph or custom orchestration layers).
The Router
The entry point is no longer a retriever; it is a Router. The Router is an LLM call that classifies the intent. Does this query actually require retrieval?
- Query: "Write a Python function to sum a list." -> Route: Pure LLM Generation (No RAG needed).
- Query: "Why did the payment service fail last night?" -> Route: Vector Store (Logs/Docs).
- Query: "What is the stock price of NVDA right now?" -> Route: Web Search Tool.
The Retriever (as a Tool)
In this architecture, the vector database is just a tool. The Agent creates the query for the database. This allows for Query Transformation. The Agent might rewrite the user's vague question into three distinct, highly specific keyword searches to maximize recall, or generate a hypothetical document (HyDE) to search by semantic similarity to the answer rather than the question.
The Grader (The Critic)
This is the most significant addition. Once documents are retrieved, a lightweight LLM node acts as a "Grader." It scores the retrieved chunks for relevance.
- Input: User Question + Retrieved Chunk.
- Output: Binary score (Relevant / Irrelevant).
If the Grader determines the retrieved documents are noise, the system does not proceed to generation. It loops back. It rewrites the search query and tries again. This prevents hallucinations caused by "poisoning" the context window with irrelevant data.
3. The Cognitive Loop: ReAct and Plan-and-Solve
How does the agent navigate these components? We rely on reasoning strategies, primarily ReAct (Reason + Act) and Plan-and-Solve.
The ReAct Pattern
In a ReAct loop, the model generates a thought trace before taking an action.
- Thought: The user wants to compare X and Y. I have data on X, but I am missing data on Y.
- Action: Call
retrieve_technical_specs(Y). - Observation: (The system returns the database output).
- Thought: I now have specs for Y. I can perform the comparison.
- Final Answer: Generate response.
Plan-and-Solve
For highly complex tasks, ReAct can get lost in the weeds. Plan-and-Solve prompts the model to generate a multi-step manifest upfront.
- Step 1: Fetch API docs for v2.
- Step 2: Fetch API docs for v3.
- Step 3: Identify breaking changes.
- Step 4: Summarize.
The Agent then executes the plan sequentially, maintaining the state of progress. This structured thinking is what separates a chatbot from an autonomous engineer.
4. Tool Use: The Interface Between Reason and Data
The "Cognitive Core" is useless without hands. In software architecture terms, "Tools" are function interfaces defined in a schema (like OpenAI's function calling format or Tool definitions in LlamaIndex).
In Agentic RAG, we go beyond just a search_vector_db tool. We equip the agent with:
- SQL Tool: To query structured relational data (e.g., "How many users signed up last week?").
- Graph Tool: To query Knowledge Graphs (Neo4j) for deep relationship traversal (e.g., "Which dependencies does this microservice rely on?").
- Code Interpreter: To execute Python code for math or data visualization on the fly.
By giving the Agent access to structured (SQL), unstructured (Vector), and graph data, we allow it to synthesize answers that no single database could provide. The LLM becomes the join operation across disparate data sources.
5. Self-Reflection and Error Correction
The hallmark of intelligence is not knowing the answer immediately, but realizing when you are wrong. Standard RAG is "open-loop"—it fires and forgets. Agentic RAG is "closed-loop."
We implement Reflection steps at the end of the generation.
- Hallucination Check: The Agent compares its final answer against the retrieved context. Does the answer contain claims not supported by the source text? If yes, regenerate.
- Answer Relevance Check: Does the final answer actually address the user's original prompt?
If either check fails, the system increments a retry counter and loops back, perhaps with instructions to "be more concise" or "search for a different aspect."
This cyclic graph—where edges can loop back to previous nodes—is what makes the system robust. It mimics the human process of drafting, proofreading, and editing.
6. Memory Systems in Agentic Workflows
When an agent performs multiple steps to answer a question, state management becomes critical. We deal with three types of memory:
- Short-term (Thread State): This is the message history of the current execution. It contains the ReAct trace—the thoughts, tool outputs, and observations. This consumes context window space, so we must often summarize or prune it during long chains.
- Long-term (Procedural): This is the vector store itself, containing the enterprise knowledge base.
- Episodic Memory: This is where Agentic RAG gets interesting. If an agent solves a novel problem (e.g., "How to fix Error 503 on the payments cluster"), we can store that successful reasoning chain back into the vector database.
Future agents can retrieve this "episode" to solve similar problems faster, effectively "learning" without model fine-tuning.
7. Production Challenges: Latency and Guardrails
As architects, we must accept the trade-offs. Agentic RAG is slow.
A standard RAG call might take 2 seconds. An Agentic loop that reflects, rewrites queries, and performs multiple retrievals might take 15 to 30 seconds.
- UX Mitigation: We cannot show a spinning loader for 30 seconds. We must stream the "thoughts" or intermediate steps to the UI (e.g., "Reading documents...", "Analyzing conflict...", "Drafting answer..."). This keeps the user engaged.
- Cost: Multiple LLM calls per user query multiply costs. We often use smaller, faster models (like Llama-3-8B or Haiku class models) for the routing and grading steps, reserving the heavy-duty models (GPT-4o / Claude 3.5 Opus class) for the final synthesis.
- Infinite Loops: Agents can get stuck in a "correction loop" where they are never satisfied with the answer. We must implement strict
max_iterations(usually 3 to 5) to force an exit or a fallback response.
8. Conclusion
Agentic RAG represents the shift from Search to Synthesis. We are moving away from building search engines that return a list of links or snippets, toward building autonomous researchers that return answers.
By decoupling the reasoning process from the retrieval mechanism, and by introducing cyclic feedback loops, we create systems that are resilient to bad data and ambiguous queries. As we look ahead through 2026, the differentiation between "software" and "agent" will continue to blur. The database is no longer just a place to store data; it is the long-term memory for a digital cognitive entity.
The future of RAG is not about larger context windows; it is about smarter reasoning loops.