A2UI & AG-UI - The Native Interface Protocol for AI Agents

In the emerging landscape of late 2025 and 2026, A2UI (Agent-to-User Interface) and AG-UI (Agent-User Interaction) represent a paradigm shift in how AI agents negotiate, render, and interact with human interfaces.
2026-01-07T00:00:00.000Z
A2UI & AG-UI - The Native Interface Protocol for AI Agents
For the past three years, we have been trapped in a "text-stream" paradigm. Since the explosion of LLMs in 2023, the primary interface for artificial intelligence has been the chat box—a linear, ephemeral stream of tokens mimicking human conversation. While effective for queries, it is woefully inadequate for complex, multi-step engineering and architectural workflows.
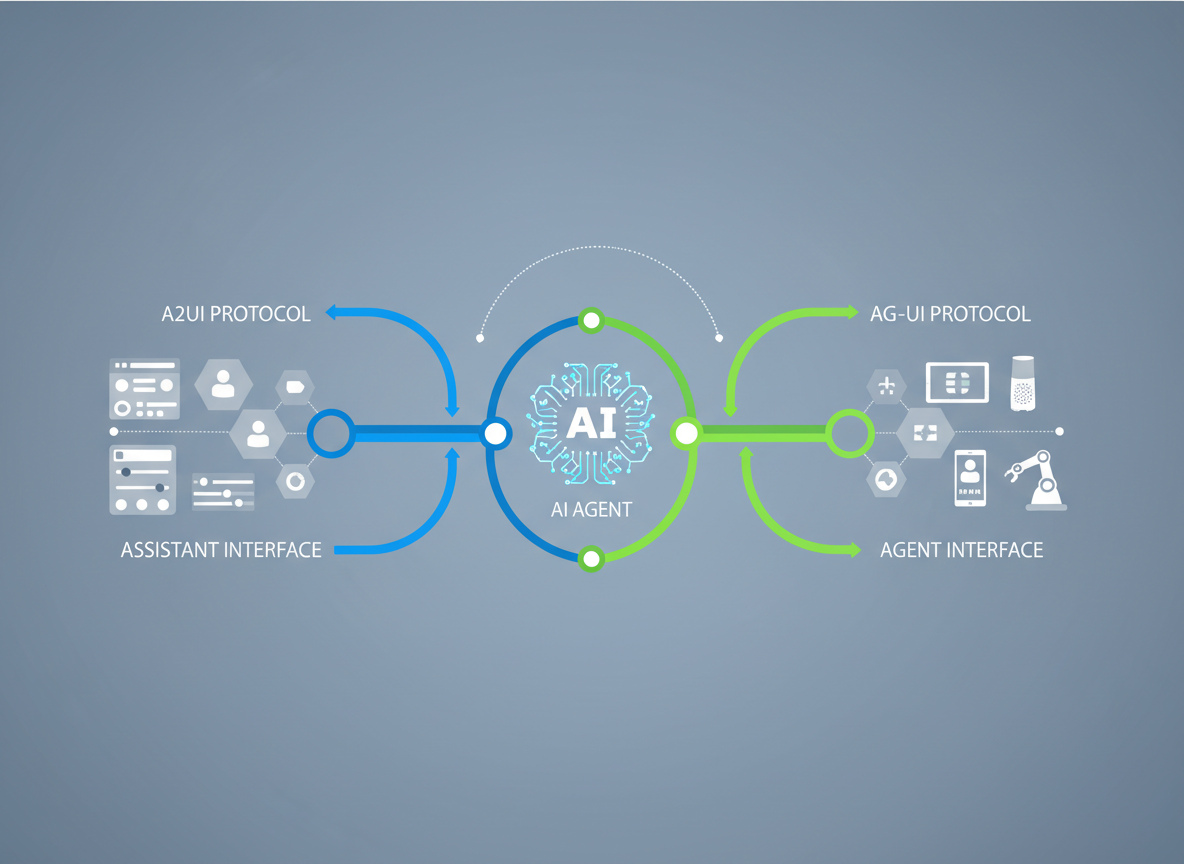
As we settle into 2026, a new standard has emerged. We are no longer building chatbots; we are building Agents that require a native way to project their intent onto a screen and a structured protocol to understand the user's environment. Enter A2UI (Agent-to-User Interface) and AG-UI (Agent-User Interaction).
These protocols represent the "Frontend" and the "Transport Layer" of the modern Agentic Stack. They allow agents to break free from the constraints of text generation and pixel-peeping Vision Models, moving toward semantic, bidirectional interaction. In this deep dive, we will explore the architecture, the security implications, and the implementation details of this interface revolution.
Contents
- The Latency of Vision vs. The Speed of Semantics
- Defining A2UI: The Generative View Layer
- AG-UI: The Protocol of Capability Negotiation
- The Semantic Handshake Architecture
- Security in Dynamic Interfaces
- Implementation Patterns for 2026
- The End of Static Dashboards
- Conclusion
1. The Latency of Vision vs. The Speed of Semantics
To understand why we need A2UI and AG-UI, we must first analyze the bottleneck of the previous generation: Vision-Language Models (VLMs).
Throughout 2024 and 2025, "Computer Use" agents largely relied on taking screenshots of a user's desktop, sending them to an inference engine, and receiving coordinate pairs (x, y) to simulate mouse clicks. While impressive, this approach is fundamentally flawed for production-grade software architecture for three reasons:
- Latency: Round-tripping high-resolution images adds significant overhead.
- Brittleness: A UI update that changes a button's color or position by 10 pixels can break the agent's logic.
- Privacy: Streaming continuous screenshots of a workspace is a non-starter for enterprise compliance.
We needed a way for the Application to tell the Agent what is on the screen, and for the Agent to tell the Application how to interact with it, without dealing in raw pixels.
This is the core differentiator of the AG-UI protocol. Instead of "looking" at a button, the agent receives a semantic representation of the button (its ID, state, and allowed actions). This reduces bandwidth usage by orders of magnitude and increases reliability to near 100%.
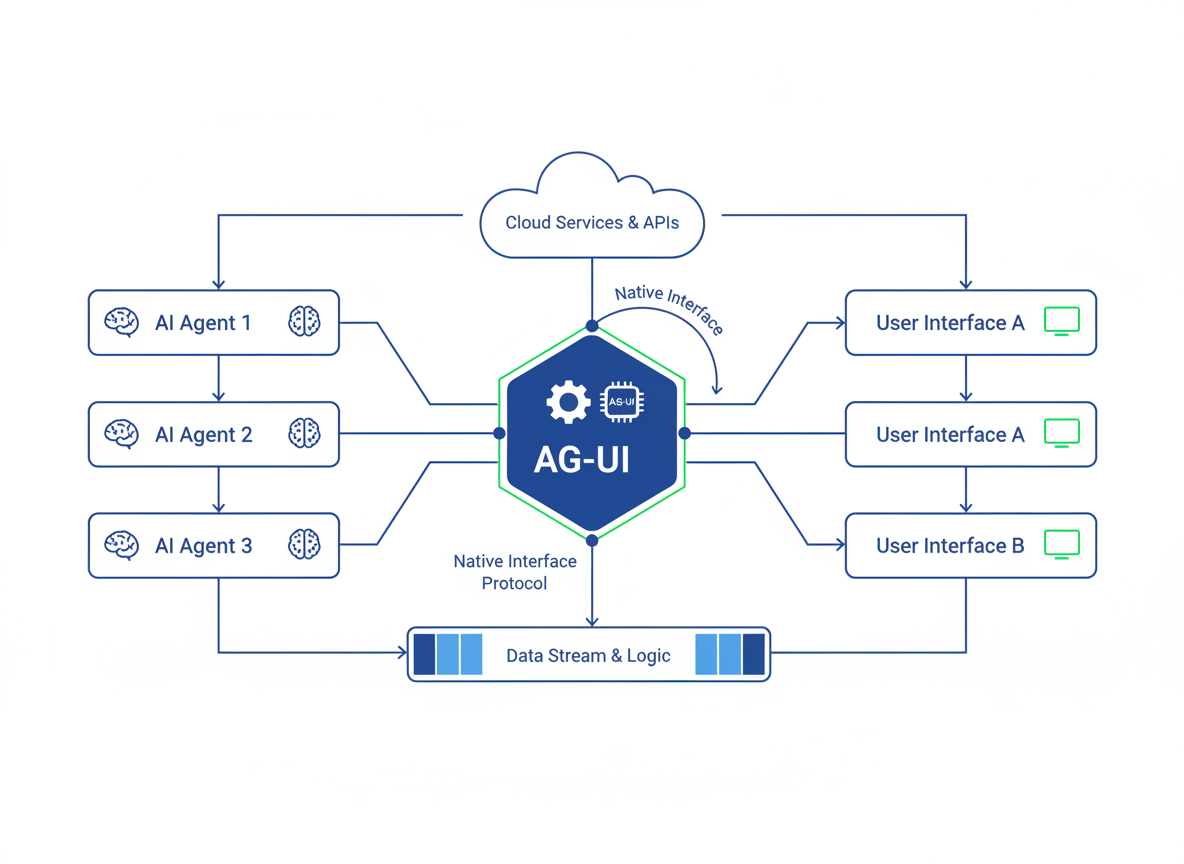
As illustrated above, the shift moves us from a "Pixel Observation" loop to a "State Synchronization" loop. This is the foundation upon which high-speed agentic interfaces are built.
2. Defining A2UI: The Generative View Layer
While AG-UI handles the data transport, A2UI handles the presentation. A2UI is the specification that defines how an agent renders ephemeral UI components to the user.
In a traditional application, the UI is static. The developer hard-codes a form, a dashboard, or a modal. In an A2UI-compliant environment, the UI is fluid. If an agent determines that the user needs to review a complex dependency graph, the agent does not describe the graph in text; it generates an A2UI payload that renders an interactive graph widget.
The Component Registry
A2UI works on the concept of a "Shared Component Registry." The host application (e.g., an IDE or a CRM) exposes a library of atomic UI elements:
DatePickersDataGridsCodeEditorsApprovalCards
When the agent constructs a response, it references these components. For example, rather than asking, "Please confirm deployment to production," the agent sends a payload rendering a "Deployment Card" with a Diff View and a physical "Approve" button.
This shifts the cognitive load from the user (who has to read text and type a reply) to the UI (where the user simply clicks).
3. AG-UI: The Protocol of Capability Negotiation
If A2UI is what the user sees, AG-UI is what the system speaks. It is the standardized protocol for Capability Negotiation.
When an agent enters a new environment—say, a cloud console or a local dev environment—it performs an AG-UI Handshake. The host system responds with a schema defining its affordances.
The Schema Definition
The AG-UI schema resembles a strictly typed OpenAPI specification but is optimized for agent consumption. It includes:
- State Tree: A JSON representation of the current application state (not the DOM, but the logical state).
- Action Space: A list of permissible functions (e.g.,
git_commit,deploy_service,update_record). - Constraints: Safety rails defined by the system (e.g., "Cannot delete production database").
By standardizing this negotiation, we eliminate hallucination regarding tool usage. The agent cannot hallucinate a delete_user function if the AG-UI schema explicitly does not list it in the Action Space.
4. The Semantic Handshake Architecture
Let's look at the architectural flow of a typical AG-UI interaction in a modern 2026 application.
- Discovery: The Agent connects to the Host via a WebSocket or gRPC stream.
- Manifest Exchange: The Host sends a
capabilities.jsonmanifest. - Observation: The Host pushes a "State Delta" whenever the underlying data changes.
- Intent Formation: The Agent formulates a plan based on the State Tree.
- Execution: The Agent sends a structured
ActionRequest. - Feedback: The Host executes the logic and returns a
ResultPayload, which may include new A2UI elements to render.
This architecture decouples the Agent's intelligence from the Application's rendering logic. The Agent becomes a logic controller, while the Application remains the view/execution engine. This separation of concerns is vital for maintaining clean architecture in large-scale AI integrations.
5. Security in Dynamic Interfaces
One of the most significant concerns we face when implementing A2UI is security. If an agent can generate UI, what prevents it from generating a deceptive interface (a "Dark Pattern") or executing malicious actions?
AG-UI solves this through Signed Intent Packets.
Every action proposed by the agent must be signed and validated against a policy engine before execution. Furthermore, A2UI elements are "sandboxed." An agent cannot inject arbitrary JavaScript or CSS. It can only instantiate components that exist in the host's safe registry.
The "Human-in-the-Loop" Widget
A critical security pattern in A2UI is the ConfirmationWidget. For high-stakes actions (like financial transactions or infrastructure destruction), the AG-UI protocol enforces a mandatory "Human-in-the-Loop" step.
The agent cannot execute the function directly. Instead, it must render a specific A2UI component that requires a physical user interaction (a click or a biometric auth) to release the cryptographic token required to execute the backend function. This ensures that the agent serves the user, rather than bypassing them.
6. Implementation Patterns for 2026
For engineers looking to implement these protocols today, we typically see a hybrid approach using JSON Schema for structure and WebComponents for rendering.
The Server-Side (AG-UI)
On the backend, we define our capabilities using Pydantic models (in Python) or Zod schemas (in TypeScript). These are serialized to JSON and served via a standard endpoint, typically /.well-known/ag-ui-manifest.
{
"protocol": "ag-ui/1.2",
"capabilities": {
"file_system": ["read", "write"],
"network": ["http_get"]
},
"ui_components": ["Spinner", "MarkdownBlock", "ActionCard"]
}
The Client-Side (A2UI)
On the frontend, we utilize a renderer that maps the Agent's JSON response to React, Vue, or Svelte components.
When the agent sends:
{
"type": "render",
"component": "ActionCard",
"props": {
"title": "Merge Conflict Detected",
"options": ["Accept Current", "Accept Incoming"]
}
}
The frontend framework dynamically hydrates the ActionCard component. This allows the interface to feel "native" to the application, maintaining branding and styling, even though the layout was decided by an AI.
7. The End of Static Dashboards
The long-term implication of A2UI is the death of the static dashboard. In traditional software, we build "one-size-fits-all" interfaces. We guess what data the user might want to see and arrange it in a grid.
With A2UI, the dashboard becomes intent-driven.
If I log into my cloud console to debug a latency spike, the Agent (via A2UI) should hide the billing widgets and user management tabs. It should construct a bespoke view showing only the latency graphs, the relevant server logs, and the database query performance.
The interface morphs to fit the task. We are moving toward "Just-in-Time Interfaces"—UIs that exist only as long as the problem exists, and dissolve once the task is complete. This reduces cognitive load and allows engineers to focus purely on the signal, not the noise.
8. Conclusion
The transition from Chat UI to Native Agent Interfaces (A2UI & AG-UI) is the defining technical shift of 2026. We are moving away from treating AI as a conversational partner and toward treating it as a systemic extension of the operating system.
By adopting AG-UI, we ensure our agents are performant, type-safe, and secure. By adopting A2UI, we ensure that the user experience remains rich, interactive, and human-centric. As architects, it is our responsibility to build these layers not just for efficiency, but for the clarity and safety of the humans operating these increasingly powerful systems.
The future of software isn't just about better algorithms; it's about better interfaces between silicon intelligence and human intent.